MadCap Flareで作ったファイルセットがあって、これを翻訳したいのだけれど、どうしたらいいのでしょうか。
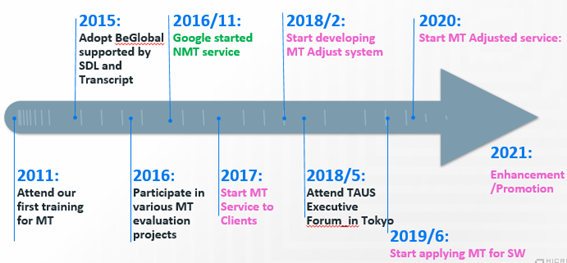
そんなお問い合わせを頂くことがあります。デプロでは過去15年にわたり、
MadCap Flareを使って作成されたソースファイルの翻訳フローについて、ナレッジを蓄積してきました。
ファイルセットを丸ごとお渡しいただければ、翻訳用ファイルセットの作成(必要な場合、設定のカスタマイズも含む)、翻訳、コンパイル、チェック、最終出力、アセットの管理まですべておまかせいただけます。
・MadCap Flareとは?
MadCap Flareはオーサリングツールのひとつで、xmlベースのシングルソースから複数のアウトプットを生成できるツールです。たとえば、PDFとHTMLの双方を出力したいとき、製品が複数ある場合、共通のファイルは共有し、製品固有のファイルは別々に処理して最終的に製品ごとのPDFやHTMLを出力したりできます。
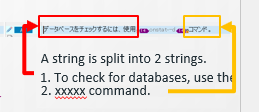
翻訳する際には、翻訳対象のファイルをMadcap独自の設定を適用して、TradosなどのCATツールに読み込み、翻訳します。翻訳完了後、ターゲット言語でファイルをエクスポートし、MadCap Flareのファイルセットに戻し、コンパイルして出力します。イメージは以下のとおりです。ファイルセットの中に含まれている画像も翻訳します。画像キャプチャがある場合はローカライズ画像に置き換えて、大きさを整え、出力ファイルに含めます。英語のキャプチャ画像は日本語の画像と同じサイズとは限らないので、必要に応じてHTML上で調整します。
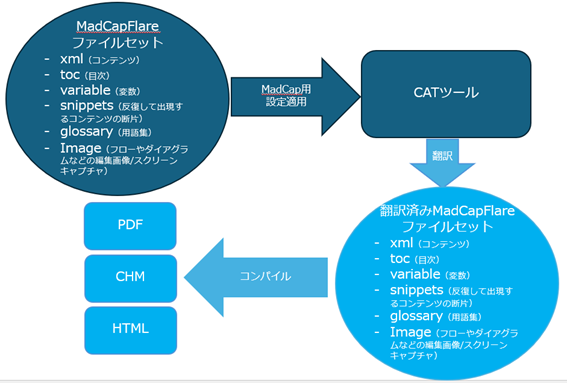
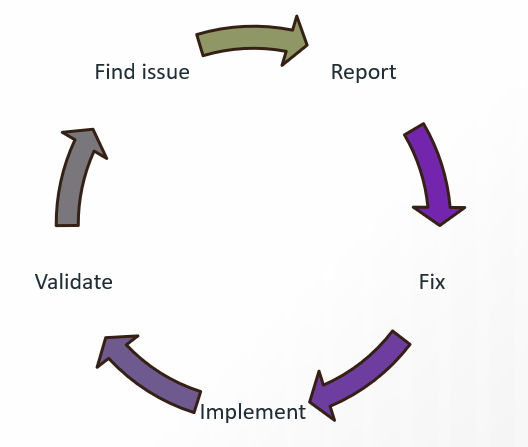
コンパイル段階では、弊社の経験豊富なエンジニアがファイルセットに含まれるCSSファイルなどを日本語環境に合わせて調整します。その後、コンパイルしてPDFの場合は、1ページずつ、OLHの場合は、HTMLを1ファイルずつ比べて、チェックを行います。
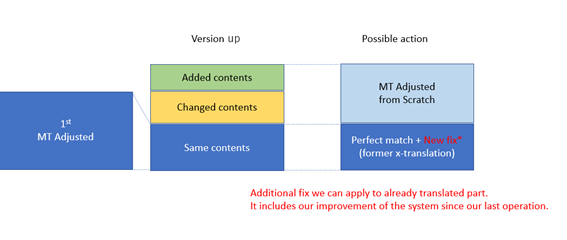
ここで、翻訳の段階で気を付けなければいけないこと、翻訳メモリに何らかのマーキングをいれておく必要が出てくると、翻訳のスタイルガイドに指示を加えたり、翻訳メモリにマーキングを追加します。CATツールでは処理できないものはCATツールからエクスポートしたターゲットファイルに処理を加えます。次回、同じところが発生すると思われる個所はスクリプト化しておきます。この処理により、MadCap Flareソースファイルが更新された場合、バージョンアップされた場合に効率よくファイル処理が出来ます。
・エンジニアコストの算出方法
デプロではMadCap Flareのプロジェクトをハンドリングする際のエンジニアリングコストは、出力ベースで以下のメトリックに従ってお見積もりしています。
PDF:40ページ/1時間
OLH:100トピック/1時間
CHM:デコンパイルしたHTMLの数により上記OLHのメトリック 100トピック/1時間
例:出力がPDF、CHM、OLHの3種類で
PDF(120ページ)、HTML(Online Help)(230ファイル)、CHM(デコンパイル後200ファイル)の場合
PDF出力:計5時間
日本語環境のセッティング 1時間
コンパイルチェック 120ページ /40=3で3時間とカウント
最終出力 1時間
OLH出力:計4.5時間
日本語環境のセッティング 1時間
コンパイルチェック 230ページ /100=2.3で2.5時間とカウント
最終出力 1時間
CHM出力:計4時間
日本語環境のセッティング 1時間
コンパイルチェック 200ページ /100=2で2時間とカウント
最終出力 1時間
なお、翻訳メモリの適用、過去のファイルからのパーフェクトマッチ処理等は、エンジニアリングコストとは別に翻訳前のファイル処理として、プロジェクトファイル1ファイルに付き1時間分のコストがかかります。
・アセット管理
翻訳終了後は、翻訳メモリ、バイリンガルファイルに必要なマーキング、カテゴリを追加して次回の更新用のアセットを作成いたします。こちらは特別な処理がない限り、プロジェクト管理費に含まれます。
不明点がございましたら、どうかお気軽にお問い合わせください。