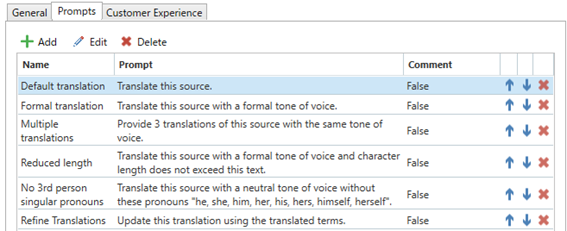
皆さんはTradosのエディターで翻訳する際、書式タグの表示はどのように設定していますか?
「表示」タブの「オプション」セクションにある以下の部分で設定でき、「タグ テキストなし」、「部分的なタグのテキスト」、「完全なタグのテキスト」、「タグID」があります。
翻訳時には、「部分的なタグのテキスト」または「完全なタグのテキスト」に設定し、書式タグがboldなのか、italicなのか、または参照タグなのかを確認しながら翻訳すると便利です。
ただし、見直し段階では、「タグID」表示を使用し、原文とタグのID番号を一致させることを推奨します。
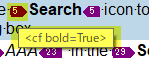
このタグID番号は、文書内の各タグのペアとプレースホルダタグに自動的に割り当てられる一意の識別子です。この表示方法では、一見書式タグの種類は把握できませんが、タグの上にカーソルを合わせると、以下のようにタグの内容がツールチップに表示されます。
なぜ「タグID」の表示を推奨するかというと、タグIDが原文と一致しない状態で訳文を翻訳メモリ(TM)に登録すると、次回のTM更新のタイミングでタグそのものの情報がTMから抜け落ちてしまうからです。
実験してみましょう。
サンプルテキスト
Double-click the Search icon to open the Search Files dialog box. Then, enter “AAA” in the Search Files dialog box.
をTradosで翻訳してみましょう。
「完全なタグのテキスト」を選択すると、boldタグはすべて<cf bold=True>と表示されます。
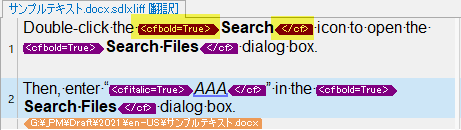
これを「タグID」の表示にすると、それぞれ5や11、29のようなID番号で表示されます。
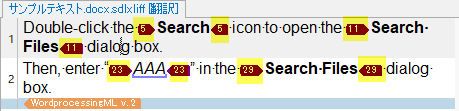
空のTMを作成し、太字の箇所はすべて同じboldタグなので、ID番号5のタグをコピーして翻訳してみます。

5のタグにカーソルを合わせると、ツールチップに<cf bold=True>と表示され、タグの内容を把握できます。

では、同じTMで少し異なるサンプルテキストを翻訳してみます。
Double-click the Search icon to open the Advanced Search dialog box. Then, enter “AAA” in the Advanced Search dialog box.
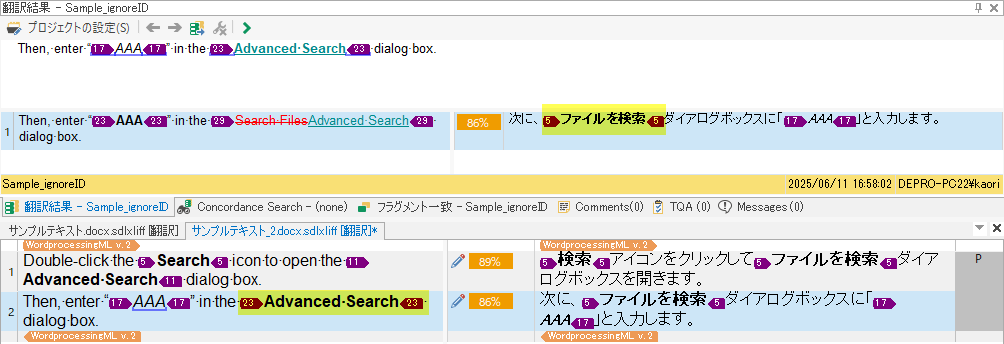
この段階では、2文目のSearch FilesからAdvanced Searchに原文が変わった箇所のboldタグは、タグID番号が異なっていても同じboldタグと判断され、TMからタグのついた訳文を取得できます。「Advanced Search」に合わせて翻訳を変更し、タグID番号はズレたままで確定します。
訳を追加したTMを使用し、新しいプロジェクトで下記のサンプルテキストを翻訳してみましょう。
Click the Search icon to open the Global Search dialog box. Then, enter “BBB” in the Global Search dialog box.
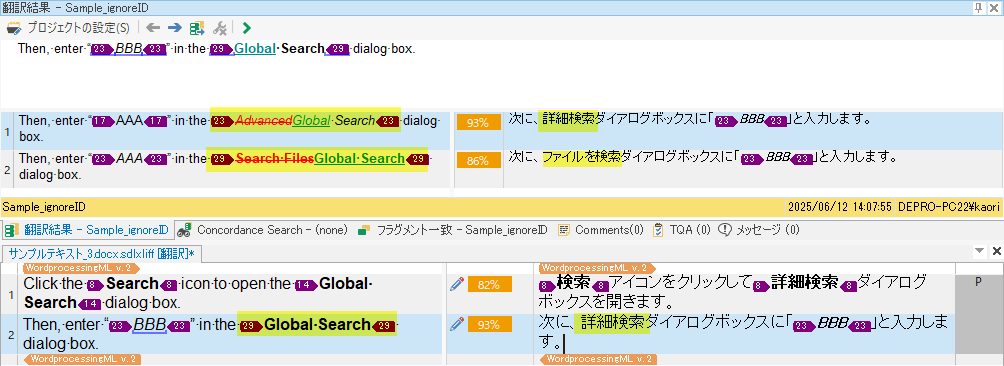
すると、1文目はタグのついたあいまい一致の訳文を取得できましたが、2文目のエントリでは、TM内の訳文からboldタグの情報が消えてしまいました。
このようなエントリが頻出すると、改めてタグを付ける作業が増え、作業効率が悪くなるほか、原文側ではタグの変化がないように見えるため、訳文にタグを付け忘れるミスにもつながります。
タグID番号が一致していなくても、Trados上の通常の検証機能ではエラーにはなりません。もちろん、タグの削除はエラーになるのでそこで気付くこともできますが、やはり余分な修正作業が増えてしまいます。デプロでは、納品時のTMの品質を維持するためにも、翻訳時には原文と訳文のタグIDを一致させることをお願いしております。